
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
Tags
- 참고자료 https://velog.io/@imok-_/javascript-dom-bom-%ec%9d%b4%eb%9e%80
- https://developers.kakao.com/
- https://ittrue.tistory.com/90
Archives
- Today
- Total
쿠쿠더님의 블로그
데이터베이스 1일차(Mysql 다운로드와 SQL 기초 쿼리문) 본문
- 데이터베이스 란?
- 데이터베이스 장점 단점
- SQL
- 데이터 베이스의 발전
- 데이터베이스 관리 시스템(DBMS)
- SQL(Strurured Query Language)
- 데이터베이스의 작업 단위 트랜잭션
- 작업 단위의 원칙
- MYSQL
- 관계형 데이터베이스의 개념
데이터 베이스란 ?
| 정보를 규칙적 체계적으로 저장 관리 하기 위한 시스템이다. |
| 소프트웨어를 개발할때 필요한 데이터를 효율적으로 관리 하기위해서 사용하는것. |
| 장점 | 단점 |
| 데이터 독립성 | 비용적인 문제 ( 공짜도 많은) |
| 데이터의 중복 통제 가능 | 백업과 회복 방법이 복잡하다. |
| 데이터 동시 공유 | 중앙 집중 관리로 인한 취약점 존재 |
| 데이터베이스 권한 검증을 통한 보안 |
데이터 베이스의 발전
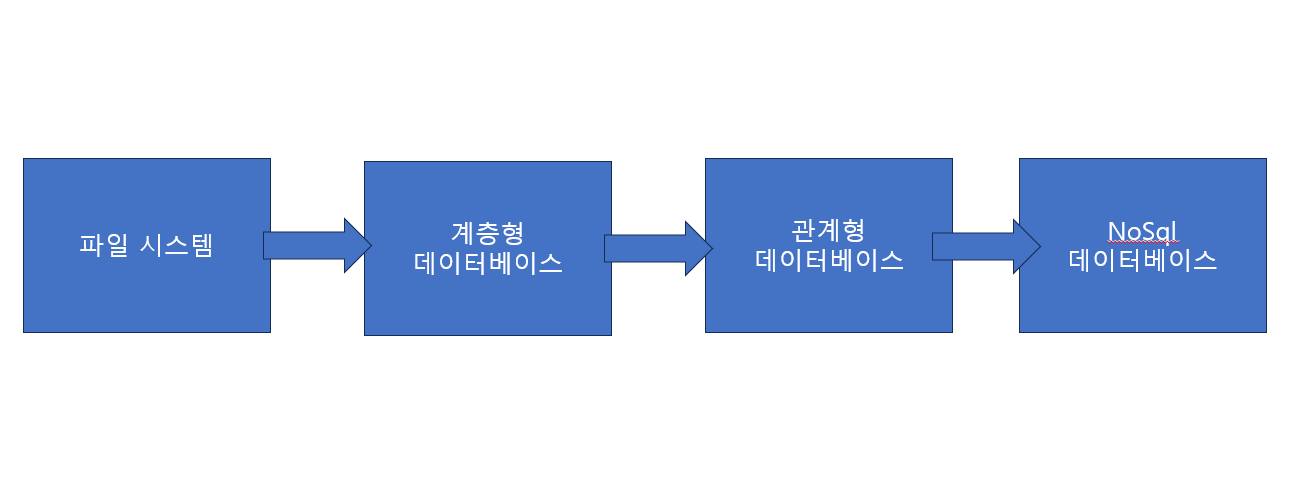
파일 시스템
| 데이터베이스의 발전 | |
| 파일 시스템 | 초기의 데이터 저장 방식은 파일 시스템이다. |
| 계층형 데이터베이스 | 트리 구조를 기반으로 하는 계층 데이터 모델 입니다. 장점 : 어떤 유형의 응용에 대해서는 빠른 속도와 높은 효율성을 제공 단점 : 어떻게 데이터를 접근하는가를 미리 응용 프로그램에 정의해야 함 데이터베이스가 생성될 떄 각각의 관계를 명시적으로 정의해야함 |
| 관계형 데이터베이스 | 데이터가 열과 행의 테이블 하나 이상에 저장되는 사전 정의된 관계로 데이터를 구성 하는 정보 모음 장점 : 데이터의 일관성과 무결성을 보장할 수 있으며, 표준화된 SQL을 사용하기 떄문에 다른 데이터베이스 모델에 비해 학습이 쉽고, 데이터 처리하는 속도가 빠릅니다. 담점 : 대용량 데이터 처리에 한계가 있고, 복잡한 데이터 구조를 처리하기에는 어렵습니다. |
| NoSql 데이터 베이스 | 비관계형 데이터베이스 유형을 가르키며 데이터베이스는 관계형 테이블과는 다른 형식으로 데이터를 저장합니다. 그리고 테이블 , 칼럼과 같은 스키마를 가지지 않고 대규모 확대가 가능하도록 수평적 확장성을 가져 대규모의 데이터를 유연하게 처리할 수 있다. 특징으로는 비일관성 , 분산저장 , Schema-less 장점 : 스키마가 없기 떄문에 유연하다. 단점 : 데이터 중복이 존재하다. ( 계속 업데이트 해야되는 단점) |
데이터베이스 관리 시스템(DBMS)
- 데이터 베이스를 생성하고 관리하는 소프트웨어
- 소프트웨어가 하는 역할을 데이터의 저장, 검색, 수정, 삭제
- 보안과 권한을 관리
SQL(Strurured Query Language)
- SQL은 관계형 데이터 베이스의 데이터를 제어하는 언어이다.
| 1.DDL(data Definition language) 데이터의 정의어 : create alter drop | 2. DML (data Manipulation language) 데이터의 조작어 :INSERT,UPDAT,DELETE | 3.DQL(data query language) 데이터의 조회어 :SELETE | 4.DCL(data controller language) 데이터의 제어어: GRATE,REMOVE |
| 테이블의 관계의 구조를 생성하는데 사용하는 구문 | 테이블의 데이터 검색, 생성, 수정, 삭제(CRUD) | 테이블의 값을 검색할때 사용 | 데이터의 사용 권한을 관리하는데 사용 |
| 테이블의 관계의 구조를 생성하는데 사용하는 구문 |
여기서 데이터베이스의 작업 단위인 트랜잭션이라고 있는데 이것도 알고있으면 좋다.
작업 단위의 원칙(ACID)
| 원자성(Atomicity) | 모든 작업이 성공해야 한다. |
| 일관성(Consistency) | 데이터의 무결성을 유지한다. |
| 고립성(Isolation) | 여러 트랜잭션이 독립적으로 실행된다. |
| 지속성(Durability) | 트랜잭션이 완료되면 영구적으로 데이터를 저장한다. |
Mysql [오픈소스로 많이 제공되고 있고 무료 데이터베이스이다.]
관계형 데이터베이스의 개념
| 테이블 | 데이터를 저장하는 기본 단위 |
| 행 | 레코드 하나의 데이터의 단위 |
| 열 | 속성과 저장할 데이터의 속성 혹은 필드라는 값의 단위 |
| 기본키 | 각 행의 고유 식별자(검색 속도에 영향을 준다.) |
| 외래키 | 다른 테이블의 관계성을 나타내는 키(제약 조건) |
설치하는방법
#환경 변수 확인
# mysql 접속
mysql -u root -p
# password 입력 창
# 경로를 시스템 환경변수로 지정
# C:\Program Files\MySQL\MySQL Server 8.0\bin
# 이런식으로 설치된 소프트웨어의 경로
# bin 폴더 경로에서 mysql 구문을 사용가능
# 시스템 환경변수로 지정
# 돋보기 누르고 시스템 환경변수 편집 창 열고
# 환경변수 버튼 누르고
# 유저에 대한 사용자 변수에 Path 클릭 새로추가로
# C:\Program Files\MySQL\MySQL Server 8.0\bin 경로 넣고 확인
show databases; # database 조회
## 데이터베이스 생성
create database 데이터베이스 이름;
# 스키마
create schme 데이터베이스 이름;
## 여러개의 테이블을 관리하는것이 데이터 베이스
drop database 데이터베이스 이름;
데이터베이스의 테이블이란?
데이터를 나타내는 표의 형태
1. 컬럼(열) : 테이블의 새로 항목 데이터의 유형의 표현
2. 로우(행) : 테이블의 가로 항목의 컬럼의 값들을 하나의 로우의 구성
| id | name | class_id | data |
| 1 | soon | 1 | 2025-03-10 |
| 2 | soon2 | 1 | 2025-03-10 |
| 3 | soon3 | 1 | 2025-03-10 |
| id | class | content |
| 1 | blockChain | text |
| 2 | blockChain | text |
RDBMS의 특징
- 중복되는 데이터를 최소화 시킨다.
- 테이블의 관계성을 맺어서 중복되는 데이터를 최소화 시킨다.
필드의 타입
1. 문자형 데이터 타입
| 데이터 타입 | 설명 |
| CHAR | 고정 길이의 문자형 설정하 문자의 크기가 5 우리가 저장한 문자의 크기가 3이면 2자리는 공백으로 채워진다. 5의 크기만큼씩 저장이 고정된다. |
| VARCHAR | 가변 길이의 문자형 정의한 길이보다 적게 사용한 경우 문자형에 맞게 데이터의 크기를 저장한다. 5자로 설정을 했는데 3자를 사용하면 3자리만큼의 데이터의 크기로 저장한다. |
| TEXT | 65,535개의 문자를 사용할수 있는 타입 너무 큰 텍스트의 내용을 사용하면 텍스트 파일로 관리하는게 효과적 , 최적화 관련해서 사용하기 위해서는 문서를 파일로 만들어서 경로를 저장한후 파일 시스템으로 가져와서 사용하는게 효과적 |
| BLOB | 이미지처럼 큰 파일을 저장할수 있는 문자열 데이터로 저장할때 사용할수 있다. ( 요즘에 사용하지 않고 클라우드 저장소나 이미지를 저장한 경로를 사용한다.) |
2. 숫자형 데이터 형식
| 데이타 타입 | 설명 |
| INT | 정수형 -2,147,483,648 ~ 2,147,483,647 (UNSIGNED가 있을때는 범위가 0 ~ 4,294,967,295 음수가 될수 없다. ) |
| BIGINT | -9,223,372,036,854,775,808 ~ 9,223,372,036,854,775,807 숫자를 사용할수 있다. |
| DOUBLE | 부동 소수와 다르게 근사값을 저장한다. 소수점의 숫자를 저장할수 있는 타입 |
3. 날짜형
| 데이터 타입 | 설명 |
| DATE | 2025-03-10 이런식으로 날짜의 데이터를 저장할수 있는 타입 yyyy-mm-dd 형식을 사용한다. |
MySQL 쿼리문
테이블 생성
//TABLE 조회
SHOW TABLES;
// TABLE 생성
CREATE TABLE store ( 필드명 타입 옵션, 필드명 타입 옵션 )
예)
CREATE TABLE store (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(10)
);
// 테이블 필드명 확인
DESC store;
// 테이블 값 추가
INSERT INTO store ( name ) VALUES ("상품 1");
//값 조회
// * 모든 내용에서 찾겠다.
SELECT * from store;
// read
// * 부분
// select 조회할 테이블의 필드명 from 테이블 이름
SELECT user_id, user_pw FROM user;
// 테이블에 soo2라는 값이 저장되어 있는지 확인하고 있으면 조회
// WHERE 조건문을 사용해서 원하는 값이 포함된 필드의 값을 찾아서 조회한다.
// WHERE 조건문에 같이 사용할수 있는 옵션 구문 AND와 OR
SELECT * FROM user WHERE user_id="soon2" OR user_pw="123";
// 테이블의 값을 수정
// SET 값을 할당하는 옵션
// WHERE에 고유 식별자를 사용해서 수정을 하면 최적화가 된다.
UPDATE user SET user_id="soon2" WHERE user_id="soon5";
//DELETE
//user안에서 id가 2인값을 삭제한다.
DELET FROM user WHERE id=2;
// user라는 테이블을 삭제한다.
DROP TABLE user;
// 기본키값이 없어
// 고유 식별자가 없다
// 기본키는 고유 식별자 하나의 테이블에 하나의 필드만 존재할수 있다
// 유니크 키는 테이블의 여러개의 필드를 생성할수 있다.
// 조회가 빈번하게 일어나지 않는 테이블은 기본키가 없이 만드는게 더 효율적이다.
// 데이터의 생성이 많이 일어난다 그럼 기본키를 생성하게 되면은 데이터를 추가하는 속도가 느려진다.
DESC user;
// 데이터베이스 사용
use [데이터베이스 이름]
// 테이블의 선택 값 조회
SELECT [필드명, 필드명2] FROM [테이블의 이름];
// 테이블의 값을 조회할때 오름차순 내림차순
// DESC 내림차순
SELECT * FROM [테이블이름] ORDER BY [필드이름] DESC;
// ASC 오름차순
SELECT * FROM [테이블이름] ORDER BY [필드이름] ASC;
과제
### 유저의 회원 정보로 가입했을때 저장할 테이블을 만들어 주세요
### 테이블의 이름은 users로 해주시고
### 저장할 유저의 데이터는 유저 아이디와 비밀번호, 닉네임, 성별, 생성시간
### 유저의 아이디는 문자열 비밀번호는 문자열 닉네임은 문자열 성별도 문자열 생성시간
### 타임스템프 DATE 타입
### 유저의 아이디는 고유한 식별자로 만들어주세요
### 유저의 아이디와 비밀번호와 닉네임은 값이 입력이 안되고 성별은 입력이 안되어도 된다.
### 시간은 입력받지말고 기본값 설정
### 아이디로 조회를 하면 해당 유저의 비밀번호를 조회해주세요
CREATE TABLE users (
user_id VARCHAR(10) NOT NULL PRIMARY KEY,
user_pw VARCHAR(20) NOT NULL,
name VARCHAR(10) NOT NULL,
gender ENUM('male','female'),
data DATETIME DEFAULT now()
);
drop table users;
select * from users;
INSERT INTO users (user_id, user_pw,gender, name) VALUES("soon123","123",'male',"soon");
INSERT INTO users (user_id, user_pw,gender, name) VALUES("soon2","1234",'female',"soon2");
INSERT INTO users (user_id, user_pw,gender, name) VALUES("soon3","1235",'female',"soon3");
INSERT INTO users (user_id, user_pw,gender, name) VALUES("soon4","1236",'male',"soon4");
INSERT INTO users (user_id, user_pw,gender, name) VALUES("soon5","1237",'female',"soon5");
INSERT INTO users (user_id, user_pw,gender, name) VALUES("soon6","1238",'male',"soon6");
select user_pw from users where user_id="soon6";
끝~~~~~~~~~

'MYSQL' 카테고리의 다른 글
| 시퀄라이즈란? (0) | 2025.04.21 |
|---|---|
| MYSQL의 인덱싱과 B-tree (0) | 2025.04.21 |
| MYSQL에 NODEJS에서 암호화 하는방법 (0) | 2025.03.18 |
| 관계형 데이터베이스와 제약조건 (0) | 2025.03.18 |
| nodejs 와 mysql 연결 (0) | 2025.03.18 |
'MYSQL' Related Articles
more
